【SikuliX】OCRの日本語読み取り精度を上げる3つの方法

SikuliXはOCRエンジン「Tesseract」を使って画像から文字を認識できます。もちろん日本語も読み取れますが、そのままOCRにかけても期待するほどの精度は得られません。
しかし、ちょっとした工夫をすれば格段に認識率を上げることが可能です。本記事ではSikuliXのOCRを使って日本語読み取り精度を向上させる三つの方法をご紹介します。これらの方法を試したうえで、SikuliXのOCRを活用できそうか考えてみてください。
SikuliXでOCRを行う方法についてはこちらの記事をご覧ください。
【SikuliX】OCRによる文字の読み取りと日本語化の方法
目次
文字サイズと解像度が最重要
SikuliXのOCRで高い精度を出すための基本は「適切な文字サイズで読み取ること」、「解像度の高い画像を用意すること」です。
上記二点の重要性を説明するため、まずは条件を満たした画像を作成しました。こちらの画像を比較対象のベースとします。例としてWikipediaページの冒頭部分の文章をお借りして、画像を作成しています。
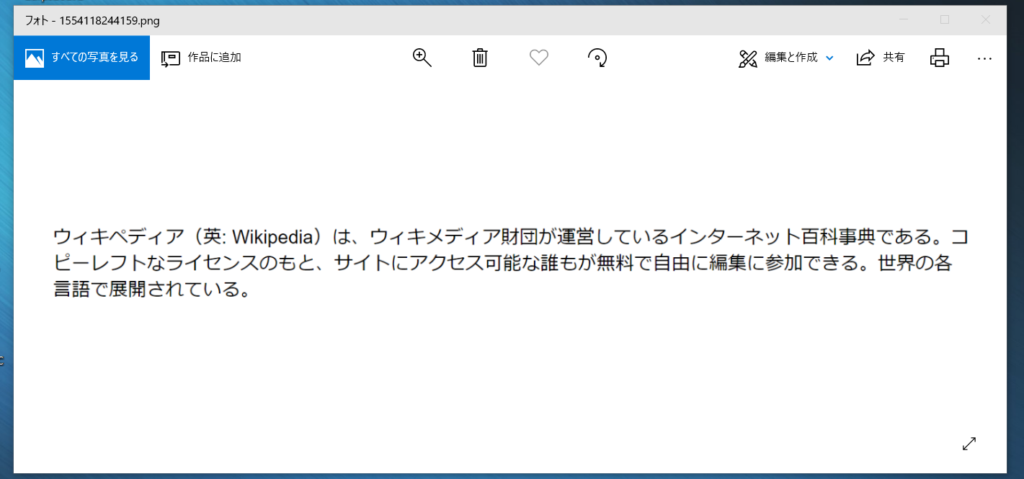
ベース画像をSikuliXのOCRで読み取った結果は以下の通りです。
ウィキペディア (英: Wikipedia) は、 ウィキメディア財団が連営しているイン夕一ネッ 卜百科事典である。 コ
ピ一レフ 卜なライセンスのもと、 サイ 卜にアクセス可能な誰もが無料で自由に編集に参加できる。 世界の各
言語で展開されている。「運」が「連」になっている、「夕」や「卜」がカタカナではなく漢字になっている、などのご認識がありますが、おおよそ正常に読みとれています。認識率も92%でした。以降、こちらの画像をベースとしてOCRの結果を比較します。
【OCR精度向上の方法1】適切な文字サイズに画像を拡大して読み取る
SikuliXでOCRの精度を上げるためにまず試すことは、適切な画像サイズに調整することです。文字が小さいと認識率がかなり下がります。画像を拡大してから読み取ることが精度を高めるコツです。
例として、ベース画像を表示しているアプリケーションのウインドウ幅を縮小しました。文字が小さくなっていることがわかります。表示している画像はベースのものと何一つ変わっていませんが、この状態でOCRを行ってみます。
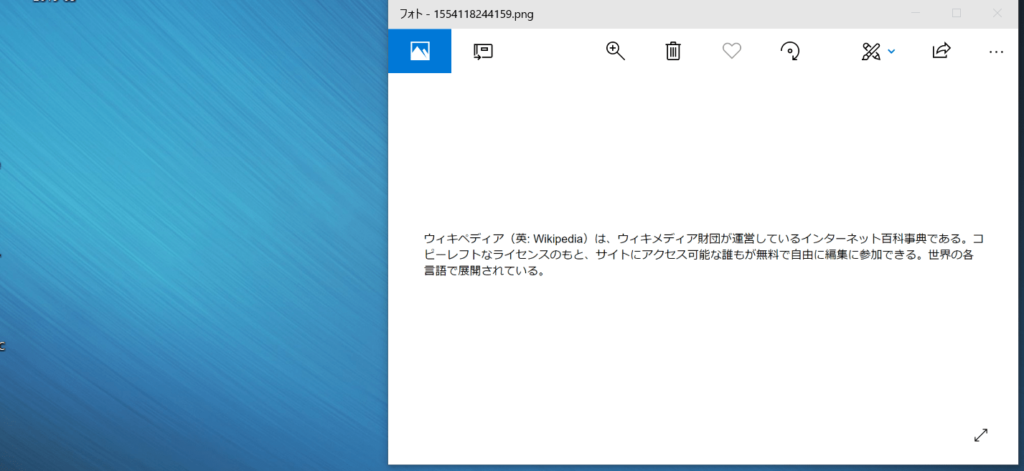
読み取り結果は以下の通りです。
ウィキべディア (英: Wikipedia) は` ゥィキメディア財団力ヾ運當しているインタ一ネッ 卜百科事典でぁる。 コ
ビ一レフ 卜なライセンスのもと` サイ トにアクセス可能な誰もヵヾ無科で自由に編集に参加できる。 世界の各
言語で展閲されている。明らかに間違っている個所がすぐに見つかります。「が」が2文字に分かれていますし、「、」も正しく認識できていません。同じ画像のはずなのに認識率も83%と10%弱低下し、文字サイズで読み取り精度が左右されることがわかります。
対処方法
SikuliXでOCRを行うときは読み取る文字が小さくなりすぎないように気をつけましょう。例えば、selectRegionなどでOCRを行う領域を選択する前に、ズームして文字を大きく見えるようにするとよいでしょう。
プログラムの例
# 画面をズームする(アプリケーションに拡大手段がなければWindowsの拡大鏡も使えます)
type(Key.ADD, Key.CTRL)
sleep(1)
r = selectRegion()
print(r.text()) # OCR【OCR精度向上の方法2】できるだけ高解像度の画像を用意する
OCRは解像度によっても大きな影響を受けるので、高解像度の画像を用意することも重要です。人の目では十分認識できる解像度でも画像が荒ければ認識率は大きく低下します。
ベース画像の解像度のみを低下させたもので、SikuliXのOCRをテストしてみましょう。
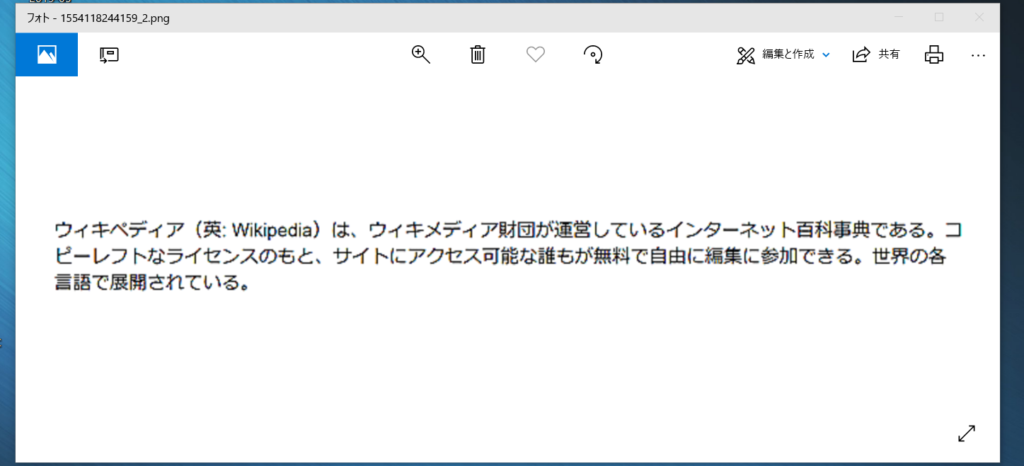
ベースの画像よりも文字が荒いのが分かるでしょうか?上記画像の読み取り結果は以下になります。
ゥィキべディア (英ニ晰kip鱒ia) は` ゥィキメディ ア財団が逓営しているイン夕-ネッ 卜百科竄典でぁる。 コ
ビ-レフ 卜なライセ〉スのもと、 サィ トにアクセス可能な誰もヵヾ無料で自由に縞集に参加できる・ 世界の各
言語で展闔されている。認識率は77%です。およそ4文字のうち1文字が間違っていることになり、実運用で活用するには厳しい数字です。目視で問題なく読める画像でも認識率が悪化したことから、SikuliXのOCR機能は解像度により大きな影響を受けることが分かります。
対処方法
OCRで読み取りたい書類をスキャンするときは、できるだけ高解像度で取り込みましょう。スキャナによっては解像度を設定できるものもあります。高解像度の画像を用意することが、SikuliXのOCRを活用するための大きなポイントになります。
小さい文字サイズ、低解像度で試すとどうなる?
スキャナで読み取った帳票などでSikuliXのOCRを試すと散々な結果になるでしょう。そのままスキャンしても文字が小さく、解像度も低いからです。文字が小さく、低解像度の画像に対してOCRをかけてみると認識率はどうなるでしょうか?ベースの画像と比較してみます。
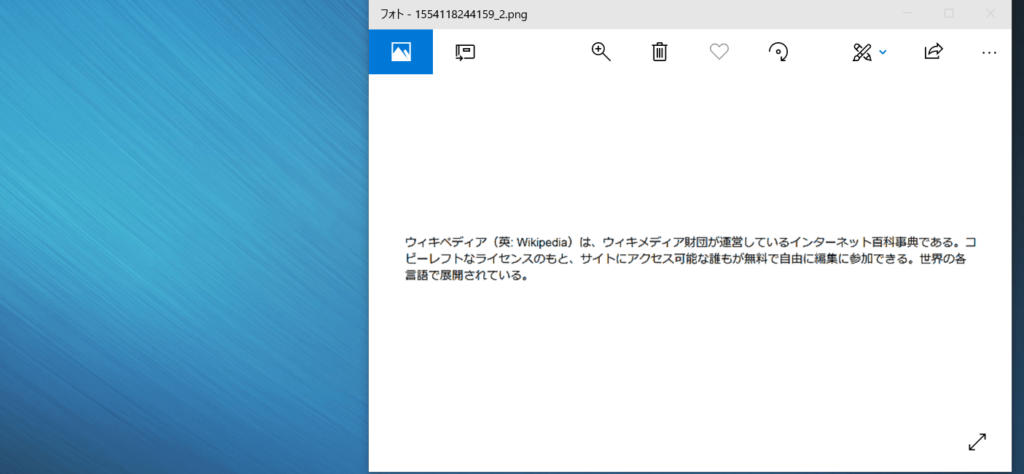
読み取り結果は以下の通りです。
ウィ制ディア (英ニ朔ki陶愴) は、 ゥィキメディア財団が潭営しているインタ-ネッ ト百科糟でぁる. コ
ビーレフ 卜なライセ>スのもと、 サィ トにアクセス可能な攫もが慧料で自由に縞纂に鬱加できる. 世卿各
喜魎で展闔されている.認識率は68%になり、ベース画像の読み取り結果よりも24%低くなりました。確かにこの結果を見るとSkuliXのOCRで日本語読み取りは使えないと判断しそうです。
しかし、ベース画像との違いは画像サイズと解像度のみ。できるだけ高解像度で書類を読み取り、適正なサイズに拡大することで認識率が大きく改善できます。
【OCR精度向上の方法3】ブラックリスト、ホワイトリストを設定する
読み取る対象によっては、「絶対使用しない文字なのに、OCRを使うとその文字で誤認識される」や「使用する文字の種類が限られている」といった状況があります。そんなときはブラックリストやホワイトリストを設定することでOCRの結果を調整できます。
ブラックリストの活用例
ベース画像をOCRした際に「夕」や「卜」が漢字で読み取られ、認識率を下げていました。「夕」と「卜」をブラックリストに登録し、カタカナで表示されるように調整します。
tr = TextOCR.start()
tr.setLanguage("jpn")
# ホワイトリストは使用しない
tr.setVariable("tessedit_char_whitelist",u"")
# 漢字の「夕」と「卜」をブラックリストに登録
tr.setVariable("tessedit_char_blacklist",u"夕卜")
r = selectRegion()
print(r.text())読み取り結果は以下の通りです。
ウィキペディア (英: Wikipedia) は、 ウィキメディア財団が連営しているインタ一ネッ ト百科事典である。 コ
ピ一レフ トなライセンスのもと、 サイ トにアクセス可能な誰もが無料で自由に編集に参加できる。 世界の各
言語で展開されている。ブラックリストに設定したことで、カタカナの「タ」と「ト」で認識されました。認識率も96%に上がっています。
ホワイトリストの活用例
帳票などで特定の文字しか使用しない場合は、ホワイトリストを使ってOCR結果を指定した文字のみに絞れます。利用できる状況は限られますが、非常に強力です。
tr = TextOCR.start()
tr.setLanguage("jpn")
# 読み取り結果を「ウィキペディア」に制限
tr.setVariable("tessedit_char_whitelist",u"ウィキペディア")
# ブラックリストは使用しない
tr.setVariable("tessedit_char_blacklist",u"")
r = selectRegion()
print(r.text())読み取り結果は以下の通りです。
ウィキペディア ウィ キ ディ ア ィ
ィ ィ ア ア 読み取り結果からわかるように、指定した文字のみ抽出できました。
【2019/4/16追記】
OCRエンジンを変更することにより、SikuliX-OCRの精度を大幅に改善する記事を公開しました。新たなOCRエンジン(Tesseract 4)を搭載したSikuliXをダウンロードして利用できます。【SikuliX】Tesseract 4を導入してOCR精度を爆上げする方法
まとめ
SikuliXのOCRで高い精度を出すには「適切な文字サイズで読み取ること」、「解像度の高い画像を用意すること」が重要です。
文字サイズはSikuliXで調整できますが、解像度はスキャナに大きく依存します。高解像度で画像を取り込めるかが、SikuliXのOCRを活用する判断基準の一つとなります。
また、ブラックリストやホワイトリストを設定できるか検討してみましょう。活用できる状況は限られていますが、認識率が向上するように読み取り結果を調整できます。
精度を上げる方法をご紹介したものの、SikuliXのOCRは日本語読み取りの精度が高くありません。さらに高い精度を目指すにはtesseract 4.xやGoogle Cloud Visionの活用が考えられるでしょう。
