Google Cloud Vision APIのOCRを使ってPythonから文字認識する方法
こんにちは、業務自動化ツール開発担当の吉池(@valmore_myoshi)です。
今回はGoogle Cloud Vision APIのOCRを使用して画像から文字認識する方法を解説します。さまざまな言語で扱えますが本記事ではPythonを使いたいと思います。
Cloud Vision APIの精度を試したり、使い方を学ぶときにお役立てください。
目次
Cloud Vision APIとは?
Cloud Vision APIは画像認識に特化したAPIです。画像から顔を検出したり、写っているものを識別できます。本記事ではそのなかでもOCRを使ったテキスト検出に絞って解説します。
REST APIやさまざまな言語ごとに用意されているクライアントライブラリを通してCloud Vision APIを使用できます。Cloud Vision APIでできることや精度を知りたい方は画像をアップロードするだけで試せる公式デモがあります。本記事では下記画像をサンプルとして試しています。

下記が実行結果です。ラベル検出とOCRの精度がよくわかります。

料金
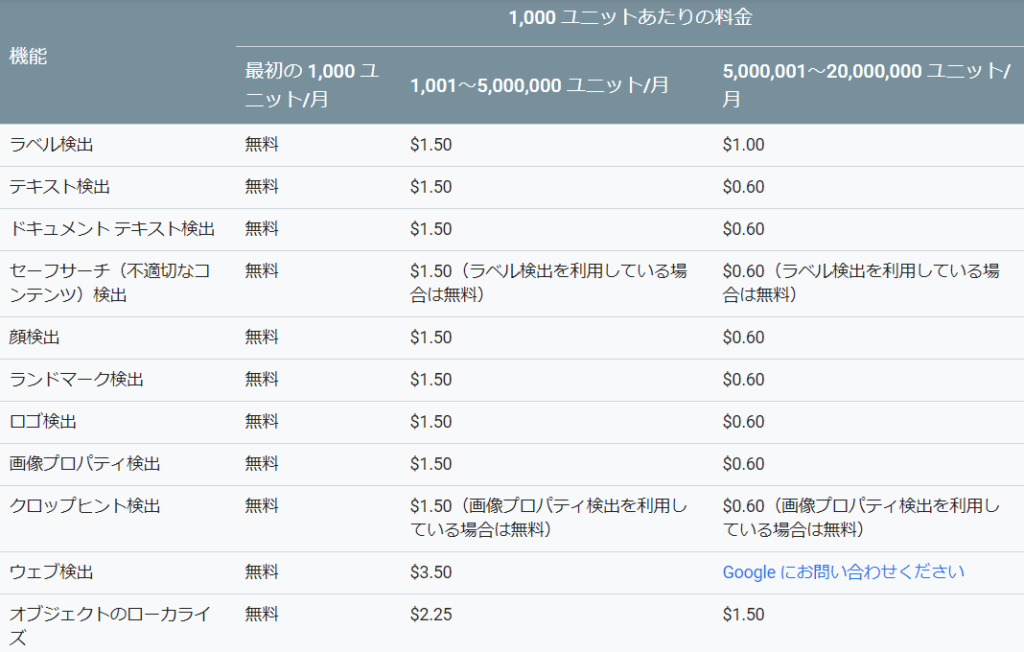
Cloud Vision APIの使用料は下記の料金表の通りです(2019/10/7現在)。ユニットとはCloud Vision APIの機能を適用する画像数を表しています。例えば、一つの画像に対して顔検出とラベル検出を適用した場合、1ユニットの顔検出と1ユニットのラベル検出と算出されます。
詳しくは公式サイトの料金ページをご覧ください。
実行環境
実行環境は下記のとおりです。Cloud Vision APIはクラウドサービスなのでOSや言語を問いません。お好きな環境でお試しください。
- Ubuntu 18.04 LTS
- Python 3.7.2
事前準備
Cloud Vision APIを使うにはGoogle Cloud Platform(GCP)上でAPIを有効化する必要があります。GCPはGoogleのクラウドサービスを管理するプラットフォームです。GCPを利用するにはGoogleアカウントが必要なので取得してください。
GCPプロジェクトを作成
GCPにアクセスし、プロジェクトを新規作成します。
新しいプロジェクトにてプロジェクト名を入力して作成ボタンを押下します。
課金を有効にする
プロジェクト作成後、プロジェクトの課金設定を有効にする必要があります。下記リンクのドキュメントにしたがって設定してください。Cloud Vision APIの使用には料金がかかりますので、料金表をご確認の上、ご利用ください。
APIを有効にする
サイドメニューの「APIとサービス」→「ダッシュボード」をクリックします。
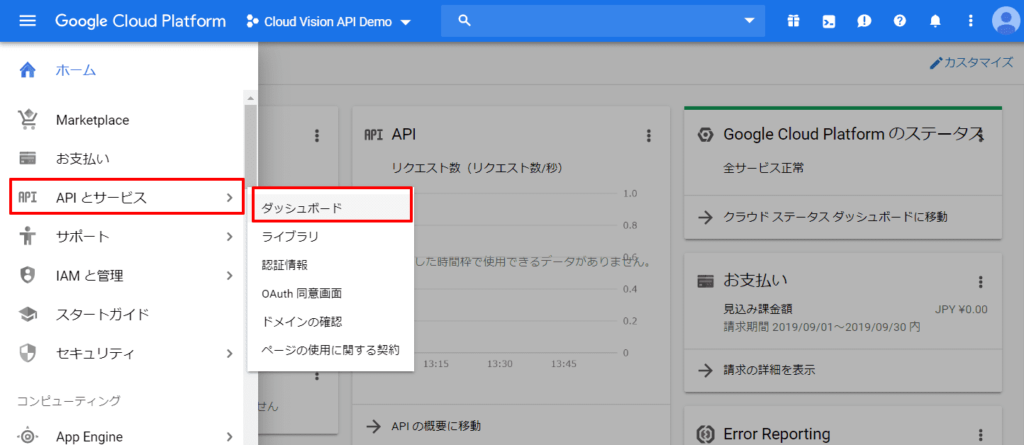
「APIとサービス」画面から「APIとサービスを有効化」をクリック。
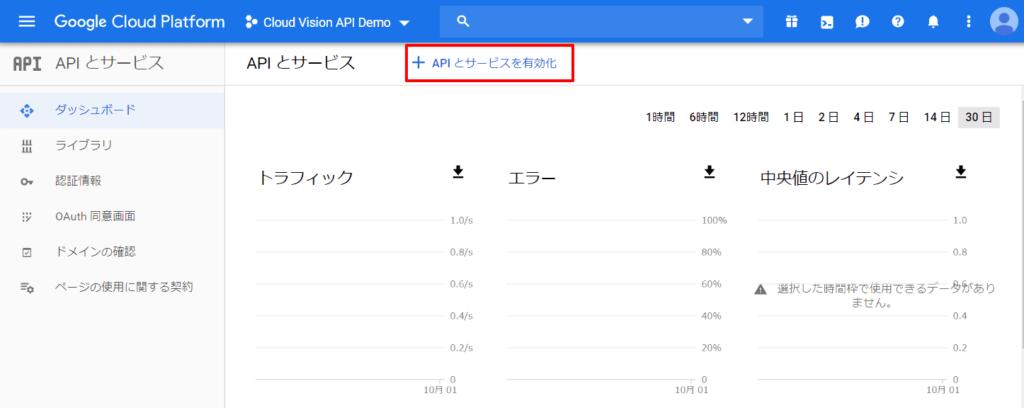
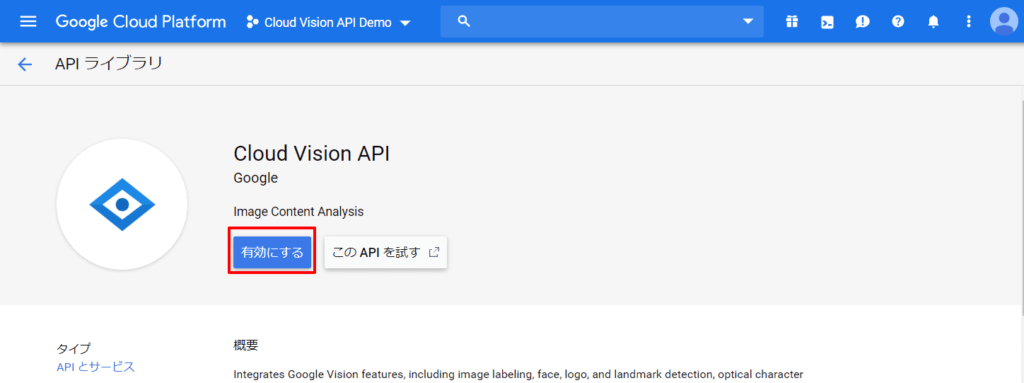
APIライブラリ画面から検索フィールドに「cloud vision api」と入力して検索。
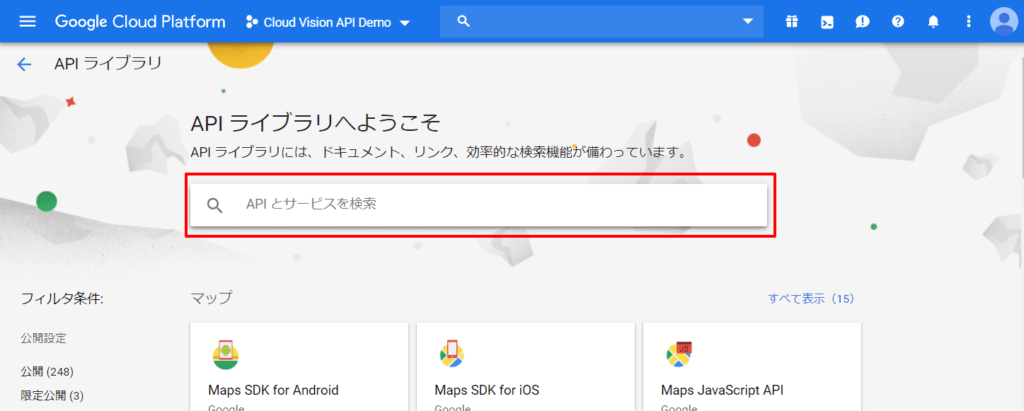
検索結果に表示されたCloud Vision APIをクリック。
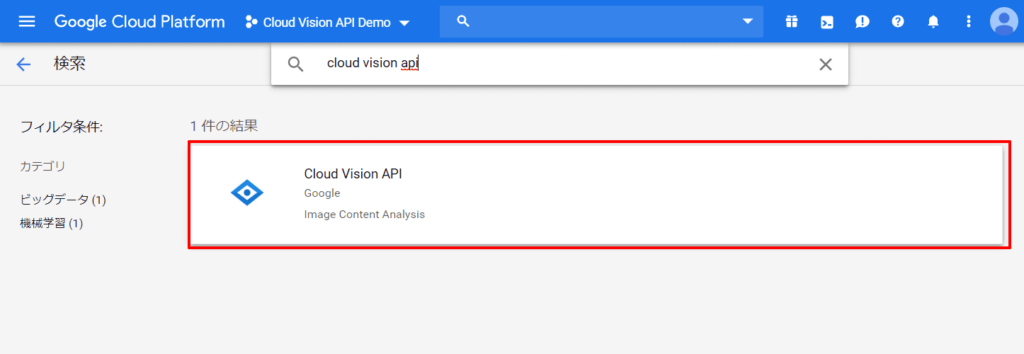
「有効にする」をクリックして、APIの有効化は完了です。
サービスアカウントを作る
続いてサービスアカウントを作ります。サービスアカウントとはアプリごとに付与されるアカウントで、権限を設定できます。
サイドメニューの「APIとサービス」→「認証情報」をクリックします。
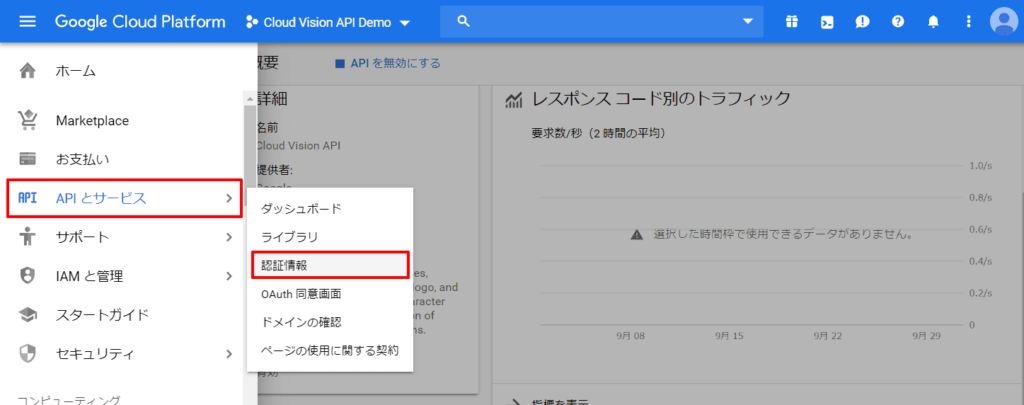
認証情報画面で「認証情報を作成」→「サービス アカウント キー」をクリック。
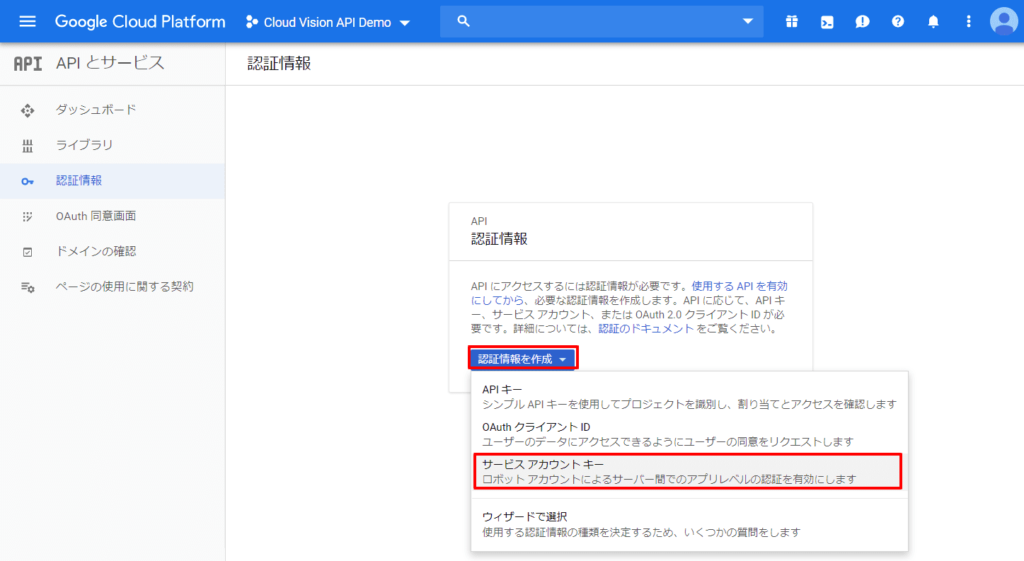
「サービス アカウント キーの作成」画面で「サービス アカウント名」を入力。役割は「プロジェクト」→「オーナー」を選択。キーのタイプはJSONで作成ボタンをクリック。
サービスアカウントの作成が完了すると秘密鍵が自動的にダウンロードされるので作業フォルダに配置します。
環境変数を設定する
サービスアカウントの作成時にダウンロードした秘密鍵のパスを環境変数に設定します。Ubuntuではexportコマンドで現在のシェルセッションのみに適用される環境変数を設定できます。永続的に環境変数を設定したければ~/.bash_profileにexport文を書きます。
export GOOGLE_APPLICATION_CREDENTIALS="path/to/your/credentials.json"
クライアントライブラリをインストールする
今回はPythonを使うのでpipでクライアントライブラリをインストールします。
pip install --upgrade google-cloud-vision
Cloud Vision APIの使い方
事前準備が完了したら、コードを書いてCloud Vision APIのOCRを使ってみましょう。OCRにはTEXT_DETECTIONとDOCUMENT_TEXT_DETECTIONの2通りあります。
単語を取得するならTEXT_DETECTION
TEXT_DETECTIONは比較的短い文字列に適しており、単語や単語の境界を取得できます。例えば、下記の看板を例にOCRを試してみます。

from pathlib import Path
from google.cloud import vision
p = Path(__file__).parent / 'load-sign.jpg'
client = vision.ImageAnnotatorClient()
with p.open('rb') as image_file:
content = image_file.read()
image = vision.types.Image(content=content)
response = client.text_detection(image=image)
for text in response.text_annotations:
print(text.description)
実行結果はこちら。看板の単語を正確に取得できています。

文章を取得するならDOCUMENT_TEXT_DETECTION
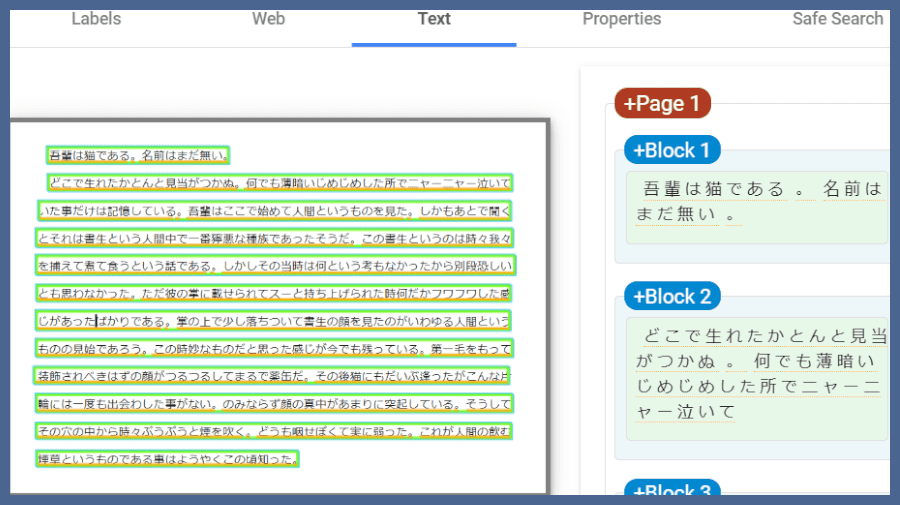
OCRで文章を取得したいならDOCUMENT_TEXT_DETECTIONを使います。文章に最適化されており、ページや段落、単語の情報を取得できます。下記画像を例に実行してみます。
from pathlib import Path
from google.cloud import vision
p = Path(__file__).parent / 'sample.png'
client = vision.ImageAnnotatorClient()
with p.open('rb') as image_file:
content = image_file.read()
image = vision.types.Image(content=content)
response = client.document_text_detection(image=image)
print(response.full_text_annotation.text)
実行結果は下記のとおりです。この結果だけ見れば誤字は一つもなく精度は100%です。

まとめ
Google Cloud Vision APIのOCR機能の使い方を解説してきました。いくつか実行結果を見ていただいたように精度はかなり高いです。少量の画像であれば無料で使えるのもお得ですね。
OCRのほかにも顔検出やラベル検出など、さまざまな機能が用意されているので、ぜひ一度お試しください。
OCRに興味がある方は、オープンソースのOCRライブラリ「Tesseract」を試してみてもいいかもしれません。下記記事で解説しているので、ぜひご覧ください。
Pythonで書くTesseract 4の基本的な使い方。APIとCLIからOCRを実行する方法
