Pythonでブラウザ操作を自動化するSelenium WebDriverの使い方

こんにちは、業務自動化ツール開発担当の吉池(@valmore_myoshi)です。
毎日の仕事で使わない日がないといっても過言ではないアプリがブラウザです。わからないことを検索したり、Webアプリを業務に導入されている方も少なくないでしょう。
そんなブラウザ操作もルーチン化していれば自動化が可能です。一度手順を決めてしまえば手動で操作するよりも早く、正確に実行できます。
そこで、本記事ではPythonを使ってブラウザ操作を自動化するSelenium WebDriverの使い方を解説します。ブラウザ作業に時間をかけている方はぜひ参考にしてください。
目次
Seleniumとは?
Seleniumとは、ブラウザ操作を自動化するツールです。公式サイトをご覧いただくとわかるようにSelenium WebDriverとSelenium IDEの2つの種類があります。
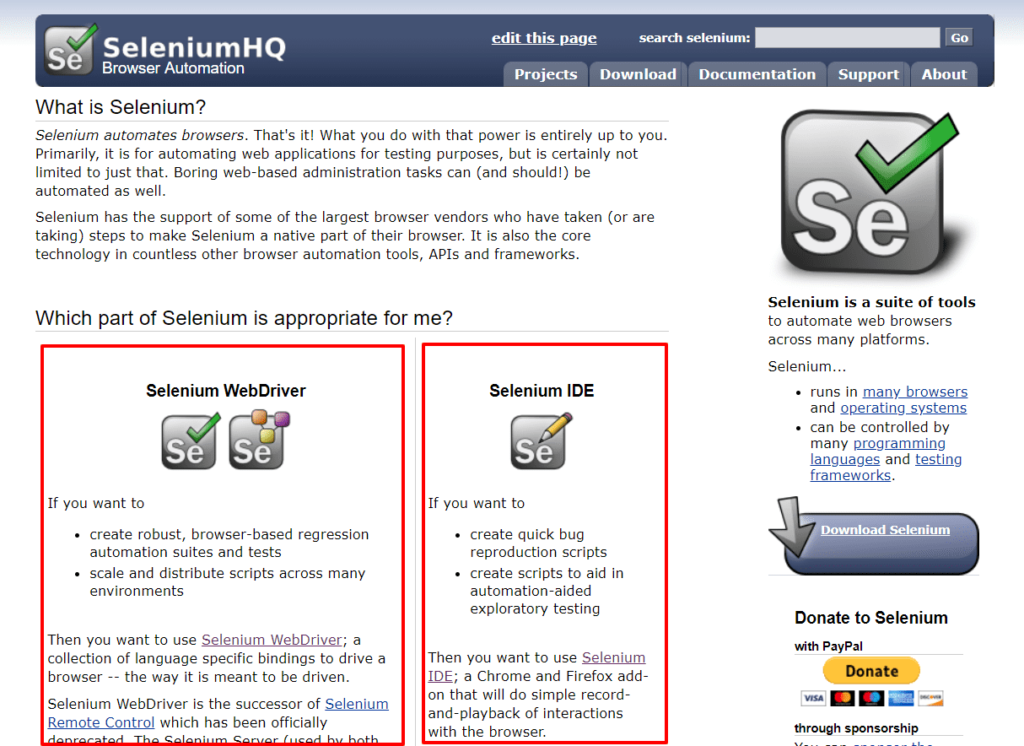
Selenium WebDriverはプログラミングを前提としたもので、「ブラウザ操作に特化したライブラリ」と「ブラウザごとに用意されているドライバー」をダウンロードして使います。
Selenium IDEはブラウザのアドオンで、自動化したい一連のブラウザ操作を記録し、その通り実行してくれます。プログラミングは必要なく、Excelのマクロ記録のように使えるため、ちょっとした作業であればSelenium IDEの方がお手軽です。
本記事ではこのSelenium WebDriverの使い方を解説しますが、Selenium IDEに興味がある方はこちらの記事をご覧ください。
Selenium IDEとは?非エンジニアでも使えるブラウザ操作自動化ツール
事前準備
Selenium WebDriverを使用するには、ChromeDriverとSeleniumライブラリが必要です。
ChromeDriverのダウンロード
ChromeDriverとは、Google Chromeを操作するために必要なドライバ(ソフト)です。ブラウザごとに専用のドライバが用意されていますが、今回はGoogle Chromeを操作します。
ChromeDriverはこちらからダウンロードできます。ブラウザのバージョンに合ったドライバを選んでください。
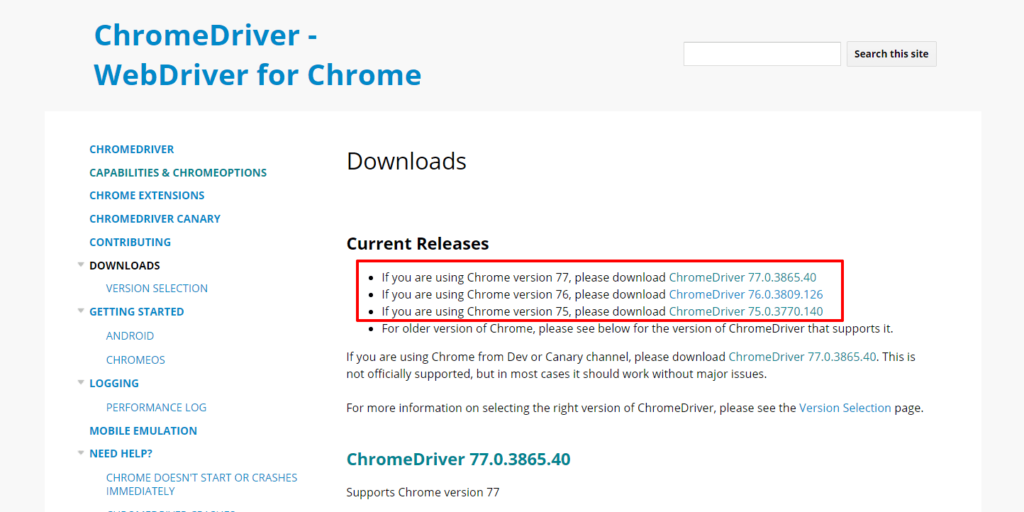
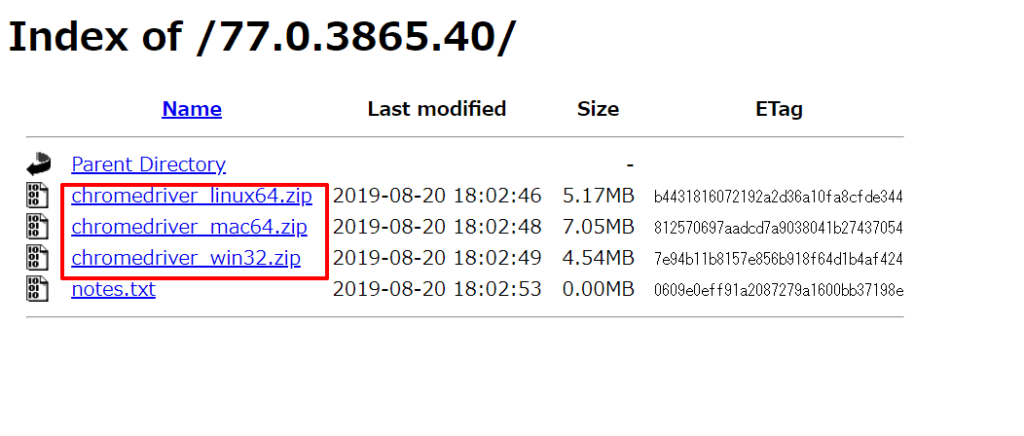
選んだ後はOSの種類を選択してダウンロードしてください。
Seleniumのインストール
SeleniumライブラリはPythonのパッケージ管理ソフトpipからインストールします。コマンドライン(Windowsならコマンドプロンプト、Macならターミナル)から下記のようにインストールコマンドを書くだけでOKです!
pip install selenium
Selenium WebDriverの基本的な使い方
事前準備が完了したら、Selenium WebDriverの基本的な使い方を見ていきましょう。流れとしては要素を見つけて、操作するという2段階のステップを踏みます。
要素を見つけるとは、Webページを構成するHTMLのうち、操作対象のタグを見つけることを意味します。ブラウザ上のWebページは下記のようにすべてHTMLで構成されているので、操作したいタグの特徴を見つけることが第一歩です。

要素を見つけたらクリックやテキストフィールドへの入力といった操作ができるようになります。例えば要素をクリックしたければ、取得した要素に続けてclickメソッドを指定するだけです。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome('path/to/your/chromedriver')
# 指定したURLのWebページへ遷移
driver.get('url')
# HTMLサンプル
# <a href=”https://example.com”>example site link</a>
a = driver.find_element(By.TAG_NAME, 'a')
a.click()
# 上記と同様
# driver.find_element(By.TAG_NAME, 'a').click()
要素の検索
要素の検索方法は複数あります。idやclassなどタグの属性を検索したり、XPathというHTMLの要素を特定する記法も使えます。一つの要素だけ検索するのであればfind_elementメソッド、複数の要素であればfind_elementsメソッドを使います。
id属性で検索
id属性は要素を一意に特定できるので一番オススメの検索方法です。操作したい要素がid属性を持っていたら喜びましょう。
# HTMLサンプル
# <div id="sample">sample div</div>
element = driver.find_element_by_id('sample')
# 上記と同様
# from selenium.webdriver.common.by import By
# element = driver.find_element(By.ID, 'sample')
class属性で検索
class属性は複数の要素に適用できます。そのため、find_elementメソッドで一つの要素を検索する場合は最初に見つかったものが取得できます。
# HTMLサンプル
# <div class="sample">sample div</div>
element = driver.find_element_by_class_name('sample')
# 上記と同様
# from selenium.webdriver.common.by import By
# element = driver.find_element(By.CLASS_NAME, 'sample')
タグ名で検索
タグ名でも検索できます。Webページ内のaタグをすべて取得するといった処理はよくあります。
# HTMLサンプル
# <a href="https://example.com/">example site link</a>
element = driver.find_element_by_tag_name('a')
# 上記と同様
# from selenium.webdriver.common.by import By
# element = driver.find_element(By.TAG_NAME, 'a')
name属性で検索
name属性でも検索できます。
# HTMLサンプル
# <input type="text" name="user-name">
element = driver.find_element_by_name('user-name')
# 上記と同様
# from selenium.webdriver.common.by import By
# element = driver.find_element(By.NAME, 'user-name')
リンクテキストで検索
リンクのテキストでも検索可能です。リンク全文を検索対象にするものとリンクテキストの一部を検索する2つの方法があります。
# HTMLサンプル
# <a href="https://example.com/">example site link</a>
element = driver.find_element_by_link_text('example site link')
# 上記と同様
# from selenium.webdriver.common.by import By
# element = driver.find_element(By.LINK_TEXT, 'example site link')
下記はリンクテキストの一部を検索する場合です。
# HTMLサンプル
# <a href="https://example.com/">example site link</a>
element = driver.find_element_by_partial_link_text('example')
# 上記と同様
# from selenium.webdriver.common.by import By
# element = driver.find_element(By.PARTIAL_LINK_TEXT, 'example')
XPathで検索
XPathはHTMLの特定の一部を指定できる記法です。これまで解説したタグの属性で解決できなければXPathを使いましょう。
XPathの記法はスラッシュ(/)で階層を区切るのが基本。途中の階層を飛ばす場合はダブルスラッシュ(//)です。属性はタグ名のあとにカギカッコでくくり、属性名に@をつけて指定します。
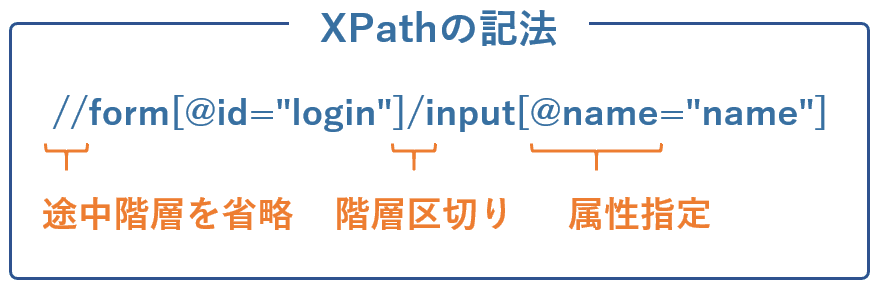
liタグなど兄弟要素に複数の要素が存在する場合はインデックス番号で特定することも可能です。
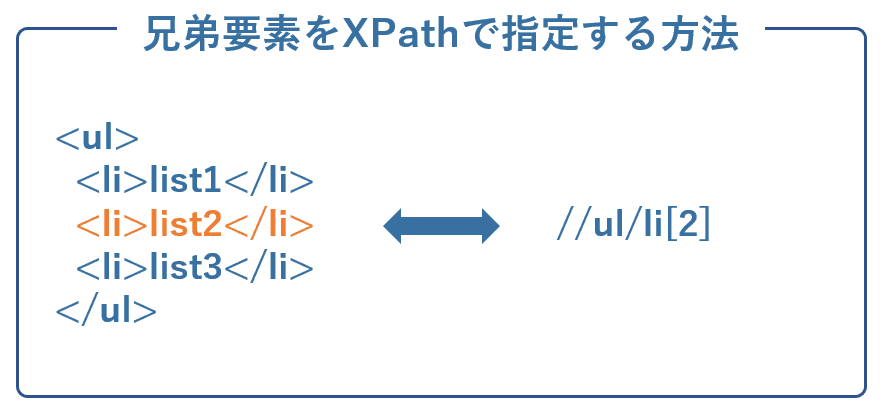
XPathで検索する場合の書き方は下記のとおりです。
# HTMLサンプル
# <ul class="list">
# <li>li example 1</li>
# <li>li example 2</li>
# <li>li example 3</li>
# </ul>
element = driver.find_element_by_xpath('//ul[@class="list"]/li[2]')
# 上記と同様
# from selenium.webdriver.common.by import By
# element = driver.find_element(By.XPATH, '//ul[@class="list"]/li[2]')
要素の操作
要素を取得したら次は操作です。クリックやテキストフィールド入力が主ですが、他にも役立つ操作があるので見ていきましょう。
クリック処理
クリック処理は取得した要素に続けてclickメソッドを指定します。
# HTMLサンプル
# <a href="https://example.com/">example site link</a>
element = driver.find_element_by_tag_name('a')
element.click()
# 上記と同様
# driver.find_element_by_tag_name('a').click()
テキストフィールドの入力
テキストフィールドの入力は取得した要素に続けてsend_keysメソッドを指定します。
# HTMLサンプル
# <input type="text" name="user-name">
element = driver.find_element_by_name('user-name')
element.send_keys('Taro Yamada')
# 上記と同様
# driver.find_element_by_name('user-name').send_keys('Taro Yamada')
フォームの送信
フォーム送信は送信ボタンをクリックしてもできますが、フォーム内の要素にsubmitメソッドを指定してもOKです。フォーム内のDOMをたどってフォーム要素を自動でsubmitします。
# HTMLサンプル
# <form action="https://example.com/users" method="post">
# <input type="text" name="user-name">
# <input type="password" name="user-pass">
# <input type="submit" value="Submit">
# </form>
element = driver.find_element_by_name('user-pass')
element.submit()
# 上記と同様
# driver.find_element_by_name('user-pass').submit()
タグ内の文字列取得
タグ内の文字列はtextプロパティで取得できます。
# HTMLサンプル
# <h1>h1 sample text</h1>
element = driver.find_element_by_tag_name('h1')
element.text
# 上記と同様
# driver.find_element_by_tag_name('h1').text
待機処理
ブラウザ操作中にページをまたがって操作するときはページの読み込みを待つ必要があります。待機処理を挟まないとページに要素が配置される前にプログラムが実行されてしまい、エラーの原因となります。そのため、必ずページ遷移時には待機処理を入れましょう。
明示的な待機処理
明示的な待機処理は、特定の条件を満たすまで指定秒数待機する処理です。条件は複数あり、ページタイトルに指定した文字列が一致するまで待機する条件やDOMの状態変化を監視するものもあります。
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By # ページタイトルがexample siteに一致するまで10秒待機 WebDriverWait(driver, 10).until(EC.title_is, 'example site') # 指定した要素がDOM上に現れるまで10秒待機 WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, 'example'))) # 指定した要素がクリックできる状態になるまで10秒待機 WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, 'example')))
暗黙的な待機処理
暗黙的な待機処理はもっと簡単で、指定した秒数待機するだけです。
driver.implicitly_wait(10)
まとめ
ブラウザ操作に役立つSelenium WebDriverの使い方を解説しました。Pythonで書かれたコードをご覧いただきましたが、それほど難しいものではありません。検索、操作、待機とブラウザ操作に必要な処理も少なく、学習コストは低いといえます。
業務でWebフォームに繰り返し入力する作業があったり、特定の情報を取得するルーチンがあればぜひ自動化を検討してください。本記事を真似していただき参考にしていただければ幸いです。
