スクレイピングとは?Webからデータを取得できるBeautiful Soupの使い方

こんにちは、業務自動化ツール開発担当の吉池(@valmore_myoshi)です。
Webサイトから自動でデータを取得したいと思ったことありませんか?競合他社の商品価格や社員の交通費計算など、毎回手動でブラウザ検索するのも面倒な話です。
そこで、今回はWebから自動でデータを取得するスクレイピングという手法について取り上げます。Pythonライブラリにはスクレイピングに役立つBeautiful Soupというライブラリがあるので、その使い方もわかりやすく解説します。
Webからのデータ収集というルーチンワークを抱えている方は、本記事を参考に自動化してしまいましょう!
目次
スクレイピングとは
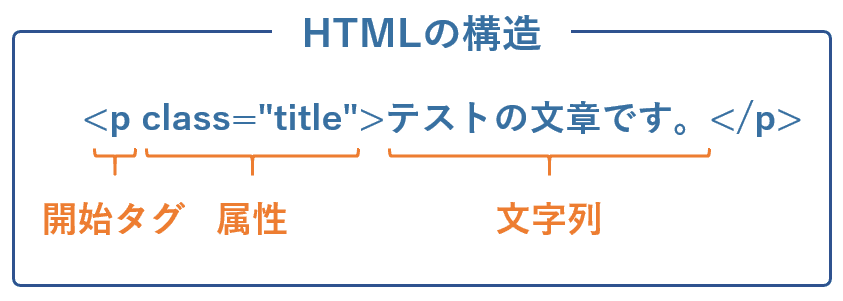
スクレイピングとはWebサイトからデータを抽出する手法のこと。WebサイトはHTMLというマークアップ言語(Webサイトを記述するための言語)で書かれており、下記のように目的のデータ以外にも余分なタグが含まれています。

そのため、HTMLの構造を把握して目的のデータのみ抽出する条件を指定することがスクレイピングの主な作業になります。
事前準備
まずはスクレイピングに必要なパッケージをインストールしましょう。Pythonのパッケージ管理ソフトpipを使って下記のコマンドでインストールできます。
pip install bs4, requests, lxml
インストールしたパッケージは下記の3つです。
- requests
- Beautiful Soup
- lxml
requestsはその名の通り、リクエスト用のパッケージです。手動であればブラウザでキーワード検索し、検索結果のなかから目的のWebページをクリックしますが、requestsはURLを渡すことで目的のWebページを直接取得できます。
Beautiful Soupは取得したWebページを解析して、目的のデータを抽出するライブラリです。HTMLのタグや属性などさまざまな条件を指定できます。
最後のXMLはパーサーです。プログラミング言語の構文を解析する役割があり、HTML一つとっても複数種類があります。今回はそのなかでも高速なlxmlパーサーを使います。
| パーサー | メリット | デメリット |
| lxmlパーサー | 動作が高速。 | 外部のCライブラリに依存。 |
| html5lib | 対応度が高い。 | 動作が遅い。 |
| html.parser | Pythonに標準で含まれる。 | 対応度が低い。 |
Webページのリクエスト
必要なライブラリをインストールしたら早速スクレイピングを始めましょう!最初はrequestsを使ってWebページをリクエストします。スクレイピングしたいWebページのURLを下記のように指定するとレスポンスが返ってきます。レスポンスの内容はtextプロパティで文字列として出力できます。
r = requests.get(WebページのURL) # レスポンスの内容 print(r.text)
指定したURLのHTMLを取得できたでしょうか?requestsの出番はここまでです。本記事では結果を統一するため、下記のサンプルHTMLを使って解説を進めます。

Beautiful Soupオブジェクトの作成
HTMLを取得できたらパーサーを指定してBeautifulSoupオブジェクトを作成します。ここで作ったBeautifulSoupオブジェクトを起点にデータ抽出条件を指定していきます。
from bs4 import BeautifulSoup html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(html_doc, "lxml")
基本的な要素の取得
BeautifulSoupオブジェクトを作成できたら早速要素を取得してみましょう。基本的な方法はタグ名をつなげて書く方法です。下記のようにBeautifulSoupオブジェクトに続けてタグ名を指定しましょう。
soup.title # <title>The Dormouse's story</title> soup.b # <b>The Dormouse's story</b>
find_allメソッドで条件に合う要素をすべて検索
次に抽出条件を指定して要素を取得します。find_allメソッドは指定した条件に一致した要素をすべて取得します。条件の指定方法がいくつかあるので見ていきましょう。
タグ名を指定して検索
find_allメソッドの引数にタグ名を指定する方法は基本です。リストや正規表現も使えます。
soup.find_all('title')
# [<title>The Dormouse's story</title>]
soup.find_all(['title', 'b'])
# [<title>The Dormouse's story</title>, <b>The Dormouse's story</b>]
キーワード引数で属性を検索
タグは複数の属性を持ちますが、属性を検索対象にするにはキーワード引数を使います。キーワード引数としてidやhrefを渡すと、指定した属性でフィルタリングできます。複数の引数を渡すことで複数の属性も検索できます。
soup.find_all(id="link3")
# [<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find_all(id="link1", href=re.compile("elsie"))
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
CSSクラスで検索
キーワード引数では属性を指定できましたが、class属性を使う場合は要注意。classはPythonの予約語で使えないからです。class属性をもとにフィルタリングしたい場合はキーワード引数としてclass_を指定します。
soup.find_all(class_="title") # [<p class="title"><b>The Dormouse's story</b></p>] soup.find_all(class_="sister") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
data-*属性は要注意
data-*で表されるカスタムデータ属性もキーワード引数として使えないので注意してください。属性を辞書形式で指定できるattrsを使えばカスタムデータ属性にも対応できます。
custom_soup = BeautifulSoup('<div data-foo="value">test</div>', "lxml")
custom_soup.find_all(attrs={"data-foo": "value"})
# [<div data-foo="value">test</div>]
正規表現で検索
タグ名やキーワード引数には柔軟に文字列を指定できる正規表現も使えます。正規表現ライブラリ「re」を使って検索条件を表す文字列パターンを正規表現オブジェクトにコンパイルして使います。
soup.find_all(href=re.compile("elsie"))
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
タグで囲まれている文字列を検索
タグではなく、タグに囲まれた文字列も検索対象にできます。text引数に文字列を指定することで合致したテキストを取得できます。
soup.find_all(text="Elsie")
# ['Elsie']
soup.find_all(text=["Elsie", "Lacie", "Tillie"])
# ['Elsie', 'Lacie', 'Tillie']
soup.find_all(text=re.compile("^E"))
# ['Elsie']
また、指定した文字列を含むタグの取得もタグ検索と組み合わせることで実現できます。
soup.find_all("a", text="Elsie")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
関数を使った検索条件の指定
検索条件に関数を指定することも可能です。下記の例では、関数の戻り値としてclass属性を持ち、かつhref属性を持たない要素を返すように指定しています。
def has_class_but_no_href(tag):
return tag.has_attr('class') and not tag.has_attr('href')
print(soup.find_all(has_class_but_no_href))
# [<p class="title"><b>The Dormouse's story</b></p>,
# <p class="story">
# Once upon a time there were three little sisters; and their names were
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
# and they lived at the bottom of a well.
# </p>,
# <p class="story">...</p>]
limit引数で取得数を制限する
find_allメソッドは条件に合った要素をすべて取得しますが、解析対象が大きくなるとそれだけ時間がかかります。すべての要素を取得する必要がない場合はlimit引数で取得数を制限できます。
soup.find_all("a", limit=2)
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
recursive引数で直下の子要素のみ検索する
find_allメソッドは指定した条件のすべての子孫要素を検索しますが、直下の子要素のみ検索したい場合はrecursive引数にFalseを指定します。下記のrecursive引数にFalseを指定した例では、htmlタグ直下の子要素のみ検索が行われ、その結果titleタグが見つからず空配列を返しているのがわかります。
html = soup.find("html")
html.find_all("title")
# [<title>The Dormouse's story</title>]
html.find_all("title", recursive=False)
# []
取得した要素から文字列や属性を抽出
要素を取得できたらタグで囲まれた文字列や属性の抽出を覚えましょう。ここでやっと目的のデータを収集できるようになります。
stringプロパティでタグで囲まれた文字列を取得
タグで囲まれた文字列はNavigableStringオブジェクトと呼ばれ、Tagオブジェクトのstringプロパティで取得できます。純粋な文字列として使用する場合はstr関数を使って文字列型に変換します。
type(soup.title.string) # <class 'bs4.element.NavigableString'> soup.title.string # The Dormouse's story type(str(soup.title.string)) # <class 'str'> str(soup.title.string) # The Dormouse's story
もしある要素(Tagオブジェクト)の子要素(Tagオブジェクト)が一つしかなく、その子要素がstringプロパティを持つのであれば、もとの要素からもstringプロパティを使えます。
soup.head.string # The Dormouse's story
nameプロパティでタグ名を取得
タグ名はnameプロパティを指定して取得できます。
soup.head.name # head
~[], attrsで属性を取得
タグは複数の属性を持てますが、辞書として属性の値を取り出せます。また、attrsプロパティで属性がまとまった辞書を取得できます。
link1 = soup.find("a", id="link1")
link1
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
link1["href"]
# http://example.com/elsie
link1.attrs
# {'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
contentsで子要素をリスト形式で取得
Tabオブジェクトにcontentsを使うと子要素をリスト形式で取得できます。
soup.find("p", class_="story").contents
# ['Once upon a time there were three little sisters; and their names were\n',
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# ',\n',
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# ' and\n',
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>,
# ';\nand they lived at the bottom of a well.']
単一データ取得したいときはfindメソッド
find_allメソッドでは、条件に合う要素をすべて取得してきましたが、一つの結果で十分ならfindメソッドを使いましょう。解析対象をすべてスキャンする必要がなくなり、高速に動作します。
soup.find("a", id="link2")
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
まとめ
スクレイピングの基礎知識やPythonライブラリBeautiful Soupの使い方を解説しました。コード例をご覧いただいたようにBeautiful Soupの使い方はシンプルでわかりやすいと思います。
そして、手動でブラウザ検索するスピードと比べるとプログラムを組んでしまった方が圧倒的に速いです。Webから取得するデータが増えれば増えるほどその恩恵を受けられるので、ぜひお試しください。
