【SikuliX】Tesseract 4を導入してOCR精度を爆上げする方法
【2020/5/19追記】
SikuliX 2.0.Xが新たにリリースされました。新バージョンではTesseract 4.xが標準で搭載されているため、SikuliX 2.0.Xのインストールをオススメします。
SikuliX 2.0.4のインストール方法と基本的な使い方。変更点・追加機能も解説
記事執筆時点(2019/4/15)で最新バージョンであるSikuliX 1.1.4では、OCRエンジンとして「Tesseract 3.0.5」が使用されています。現状のSikuliXでも画像からある程度文字を認識できますが、まだまだ精度が良いとは言えません。
少しでも精度を上げるために、本ブログでも以下のように日本語化の方法や精度の向上方法を取り上げてきました。
【SikuliX】OCRによる文字の読み取りと日本語化の方法
【SikuliX】OCRの日本語読み取り精度を上げる3つの方法
しかし、根本的に文字認識の精度を上げるにはOCRエンジン自体のバージョンアップが必要です。そこで本記事では現時点で最新バージョンであるTesseract 4を利用して、SikuliXのOCR精度を圧倒的に改善する方法をご紹介します。
SikuliXのTesseractバージョンを変えるには手間がかかるため、記事中にダウンロードリンクを配置しています。お試しになりたい方はぜひご利用ください。
Tesseract 4とは? Tesseract 3との差を比較
Tesseractは日本語にも対応したOCRエンジンです。オープンソースでライセンスは「Apache License 2.0」なので、無料で商用利用も可能です。前述したとおり、SikuliXもOCRエンジンにTesseractを使用しています。
Tesseract 4では、新たなニューラルネットワーク(LSTM)をベースとしたOCRエンジンを利用できます。SikuliXが現状使用しているバージョン3系と比較して、読み取り精度がかなり向上しています。
【SikuliX】OCRの日本語読み取り精度を上げる3つの方法で実験したように、Wikipediaページの冒頭文章で作った画像を読み取り、精度を比べてみます。差がはっきり表れるように解像度とサイズを下げた画像を使っています。
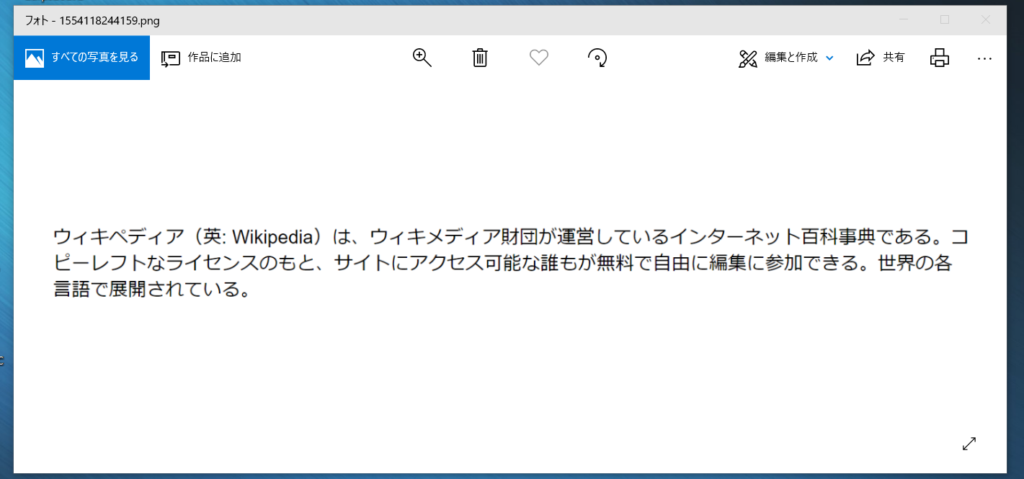
Tesseract 3の読み取り結果は以下の通りで、認識率は68%でした。半分近く間違えています。
ウィ制ディア (英ニ朔ki陶愴) は、 ゥィキメディア財団が潭営しているインタ-ネッ ト百科糟でぁる. コ
ビーレフ 卜なライセ>スのもと、 サィ トにアクセス可能な攫もが慧料で自由に縞纂に鬱加できる. 世卿各
喜魎で展闔されている.対してTesseract 4の読み取り結果は以下の通りです。
ウィ キ ペ ディ ア ( 英 : Wikipedia) は 、 ウ ィ キ メデ ィ ア 計 団 が 運営 し て いる イン ター ネッ ト 百 科 事 典 で ある 。 コ
ピー レフ ト な ライ セン ス の も と 、 サ イト に アク セス 可能 な 誰 も が 無料 で 自由 に 編集 に 参加 で きる 。 世界 の 各
言語 で 展開 され て いる 。全角の「(」と「)」が半角になっていることと、「財」が「計」となっていること以外は認識できており、認識率は97%。精度の差は圧倒的です。
Tesseract 4を利用することで、OCR精度が劇的に改善していることがおわかりいただけると思います。
SikuliXでTesseract 4を使うには?
SikuliX1.1.4で使用しているTesseractはバージョン3です。Tesseract 4を使えるSikuliXを用意したので、こちらからダウンロードしてご利用ください。ただし、ご利用は自己責任でお願いします(Windows 10環境で検証済み)。
ダウンロードしたzipファイルには以下のファイルが入っています。
・jp2.traineddata
・en2.traineddata
・sikulixide-1.1.4(Tesseract4).jar
「jp2.traineddata」と「en2.traineddata」はTesseract 4用の言語データです。「C:\Users\ユーザー名\AppData\Roaming\Sikulix\SikulixTesseract\tessdata」内に追加してください。
「sikulixide-1.1.4(Tesseract4).jar」はTesseract 4使用版のSikuliXプログラムです。「sikulix.jar」と同じように、ダブルクリックするとSikuliXの開発画面が立ち上がります。今までのSikuliXと同じように使用できますが、OCRの結果は驚くほど改善しているはずです。試してみてください!
OCRの使用例
# デフォルト文字コードの変更
import sys
reload(sys)
sys.setdefaultencoding("SHIFT_JISX0213")
# 言語設定をTesseract4用の日本語に変更
tr = TextOCR.start()
tr.setLanguage("jp2")
str = find("スクリーンショット").text()
print(str)【注意】ブラックリスト、ホワイトリストが使えない
本記事執筆時点で、Tesseract 4は【SikuliX】OCRの日本語読み取り精度を上げる3つの方法で紹介した「ブラックリスト」と「ホワイトリスト」の設定ができません。そのため、読み取る文字が限定できるのであれば、Tesseract 3のほうが適しているかもしれません。
Tesseract 3を使用する場合は、これまで通り「sikulix.jar」でSikuliXの開発画面を立ち上げ、言語には「jpg」や「eng」を指定してOCRを行ってください。
まとめ
SikuliXはTesseract 3を使っています。SikuliXで使用するTesseractをバージョン4に上げることで、驚くほど読み取り精度が向上します。
しかしながら、Tesseract 4ではブラックリストとホワイトリストが使えません。読み取る文字が限定的であれば、Tesseract 3を使うことも検討しましょう。
【2019/9/27追記】PythonからTesseract 4を使う方法を解説しました。
Pythonで書くTesseract 4の基本的な使い方。APIとCLIからOCRを実行する方法
