【SikuliX】OCRによる文字の読み取りと日本語化の方法

SikuliXを使っていて、入力だけではなく文字の読み取りも行いたいと思ったことはありませんか?例えば、「スキャナで読み込んだ書類上の文字を転記したい」などが典型例だと思います。
SikuliXではOCR(光学文字認識)エンジンであるTesseractを使って、文字を読み取ることができます。
文字の読み取りを行えると自動化できる業務の幅が大きく広がるので、ぜひマスターしましょう。
※本記事の内容はSikuliXのバージョン1.1.4で動作を確認しています。
目次
SikuliXのOCRでテキストを読み取る
SikuliXのOCR機能で文字を読み取る方法は、大きく分けて二つあります。
- スクリーンショットを事前に取得して読み取る
- Regionで指定した場所を読み取る
どちらの方法も、読み取る文字が英数字であれば問題なく動作します。
※日本語文字の読み取りには特別な対応が必要です。本記事の二章以降でご紹介します。
スクリーンショットから読み取る方法
「スクリーンショットを撮る」で取得した画像をテキスト化する方法です。
次のようにして画像をテキスト化できます。
find("スクリーンショット").text()例としてメモ帳に記載した文字をテキスト化して、SikuliXのメッセージ欄に表示させてみましょう。

【実行するプログラムコード】
str = find("スクリーンショット").text()
print(str)【実行結果】
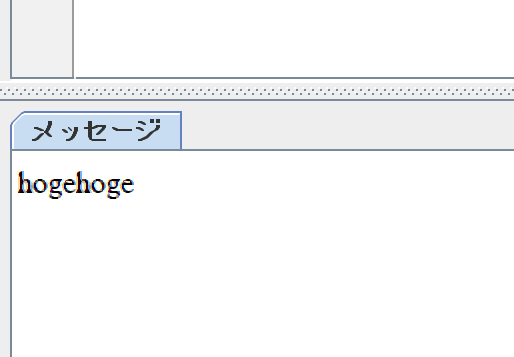
画像内の文字を読み取ることができました。
Regionを指定して読み取る方法
OCRで文字を読み取るとき、「スクリーンショットを撮る」では対応できないケースが多々あります。
なぜなら、請求書の数字など実行するたびに変わる文字は、事前にスクリーンショットを取得できないからです。
試しにメモ帳の文字を変えて、先ほど作成したプログラムを実行してみましょう。
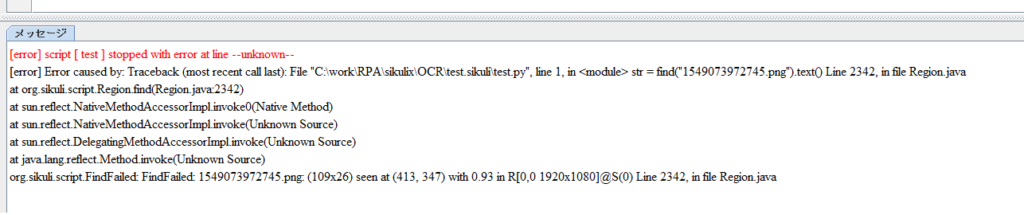
画像が見つからないのでエラーになってしまいました。
事前にスクリーンショットを撮るのではなく、テキスト化したい場所を座標の領域で指定すれば、変動する文字でもテキスト化が可能です。
座標の領域を取得するには「Region」をクリックし、指定したい範囲をドラッグします。


ではメモ帳の文字を読み取れるか試してみましょう。
【実行するプログラムのコード】
str = "Regionで取得した領域".text()
print(str)実行前にメモ帳のテキストを「fugafuga」に変更してから実行してみます。
【実行結果】
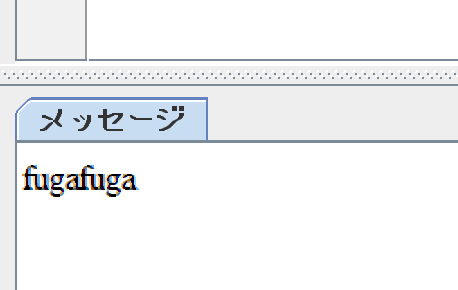
Regionを指定することで変動する文字でも読み取ることができました。
スクリーンショットの日本語テキストを読み取る
SikuliXのOCRはデフォルトの言語設定が英語になっています。この状態では日本語の文字を読み取ることはできません。
日本語を読み取るために、まずは日本語用のデータファイルをダウンロードする必要があります。こちらから日本語ファイル(jpn.traineddata)をダウンロードしましょう。
ダウンロードが完了したら、jpn.traineddataをSikuliXが読み込めるように、SikuliXのAppDataフォルダ内の「SikulixTesseract\tessdata」フォルダに配置します。私の環境では「C:\Users\ユーザー名\AppData\Roaming\Sikulix\SikulixTesseract\tessdata」というフォルダパスになりました。
これでSikuliXのOCR言語設定を日本語にできます。下のように記述して、設定を変更しましょう。
tr = TextOCR.start()
tr.setLanguage("jpn")これで日本語を読み取れるようになりました。メモ帳の日本語部分に「スクリーンショットを撮る」を行い、テキスト化を試してみます。

【実行するプログラムコード】
# デフォルト文字コードの変更
import sys
reload(sys)
sys.setdefaultencoding("SHIFT_JISX0213")
# 言語設定を日本語に変更
tr = TextOCR.start()
tr.setLanguage("jpn")
str = find("スクリーンショット").text()
print(str)【実行結果】
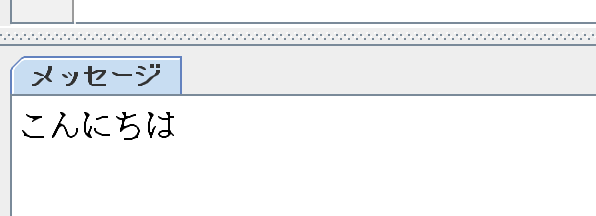
日本語の画像もテキスト化することができました。
※日本語の文字をメッセージ欄に表示するには下のようにデフォルト文字コードを変更する必要があります。
import sys
reload(sys)
sys.setdefaultencoding("SHIFT_JISX0213")Regionの日本語読み取りに対応する
前述したとおり、OCRでの読み取りにはRegionを使うことが多いと思います。ところが、Regionを使用して日本語の文字を読み取ろうとしても失敗するようです。
次のようにメモ帳の日本語文字をOCRで読み取ってみましょう。今回はRegionを使います。
【実行するプログラムコード】
import sys
reload(sys)
sys.setdefaultencoding("SHIFT_JISX0213")
tr = TextOCR.start()
tr.setLanguage("jpn")
str = "Regionで取得した領域".text()
print(str)【実行結果】
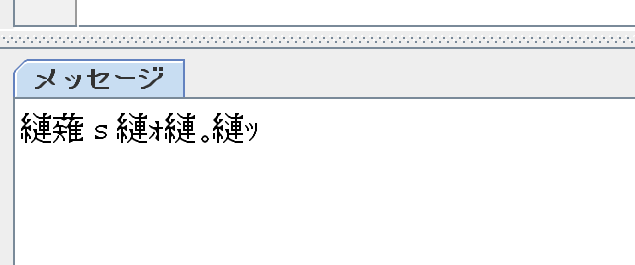
読み取り結果が文字化けしてしまい、これまで通りの方法だと正常に読み取れません。Regionを使用して日本語の文字を読み取る方法は二つあります。
- SelectRegion関数を使い、読み取る領域を実行のたび指定する
- 実行時に選択したRegionを画像化してから、OCRで読み取り処理を行う
SelectRegion関数を使う
selectRegion関数は実行時にRegionをドラッグで指定することができます。selectRegionで取得したRegionに対してなら、日本語の文字でも読み取れるようです。
selectRegionを使ってメモ帳の日本語の文字を読み取ってみましょう。SikuliXの実行中にRegionを選択する画面が表示されるので、メモ帳の日本語部分を選択してください。
【実行するプログラムコード】
# デフォルト文字コードの変更
import sys
reload(sys)
sys.setdefaultencoding("SHIFT_JISX0213")
# 言語設定を日本語に変更
tr = TextOCR.start()
tr.setLanguage("jpn")
# 実行時にRegionを取得
area = selectRegion()
print(area.text())【実行結果】
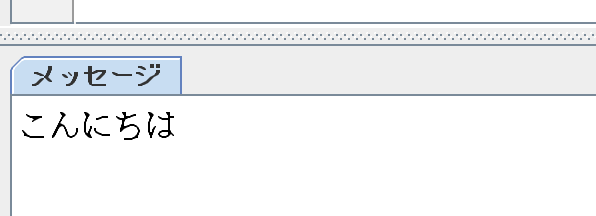
selectRegionを使って日本語を読み取ることができました。
Regionを画像化してから、読み取りを行う
selectRegionを使えば日本語を読み取れますが、読み取る回数が多くなると、何度もRegionを指定することになって効率が悪くなります。
そこで事前にRegionを指定しても、日本語の文字を読み取る方法があるのでご紹介します。ただRegionを指定するだけだと日本語を読み取れませんが、Regionのスクリーンショットを取得して画像化してから読み取りを行うことで読み取れるようになります。
「getScreen().capture(“選択したRegion”)」でRegionのスクリーンショットを取得できます。取得したスクリーンショットのファイルパスはfilename属性から参照できます。そこから画像を読み込み、OCRでテキスト化します。
メモ帳で試してみましょう。
【実行するプログラムコード】
# デフォルト文字コードの変更
import sys
reload(sys)
sys.setdefaultencoding("SHIFT_JISX0213")
# 言語設定を日本語に変更
tr = TextOCR.start()
tr.setLanguage("jpn")
# Regionのスクリーンショットを取得
img = getScreen().capture(“選択したRegion”)
# Regionをテキスト化して表示
print(find(img.filename).text())メモ帳内の文字を変更してから実行します。
【実行結果】
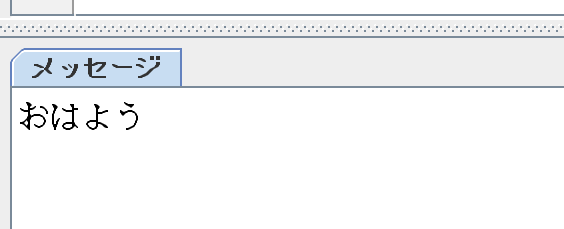
Regionを使って、日本語を読み取ることができました。
【2019/4/3追記】
OCRの精度を上げる方法はこちらの記事で紹介しています。SikuliXでOCRを活用したい方は参考にしてください。【SikuliX】OCRの日本語読み取り精度を上げる3つの方法
【2019/4/16追記】
OCRエンジンを変更することにより、SikuliX-OCRの精度を大幅に改善する記事を公開しました。新たなOCRエンジン(Tesseract 4)を搭載したSikuliXをダウンロードして利用できます。【SikuliX】Tesseract 4を導入してOCR精度を爆上げする方法
まとめ
SikuliXのOCR機能で文字を読み取る方法から、日本語の読み取り方までご紹介しました。日本語を読み取るには言語データをダウンロードしてから、言語設定を日本語にする必要があります。
Regionを使って日本語を読み取るためにはひと工夫必要です。実行時にRegionを選択しても問題ない場合は、selectRegion関数を使いましょう。事前に指定したRegionは、実行時にスクリーンショットを取得すると読み取ることができます。
SikuliXのOCRでは日本語の読み取り精度は高くありません。OCRを使わずに読み取る方法はないか、まず他の選択肢を検討することをおすすめします。OCRを使用する場合は、読み取った内容を過信せずに必ずチェックして使用しましょう。
